Pretoria is a tool for manipulating Oracle indexfiles. Basically, Pretoria parses the indexfile and performs a search and replace on the storage parameters - it then separates table create statements and index create statements. These files can then be used to pre-create all database segments, basically reorganizing your database. Pretoria can also be used as a pretty printer ( hence the name, pretty oracle -> pretora -> pretoria ) for indexfiles.
So how does Pretoria work ?
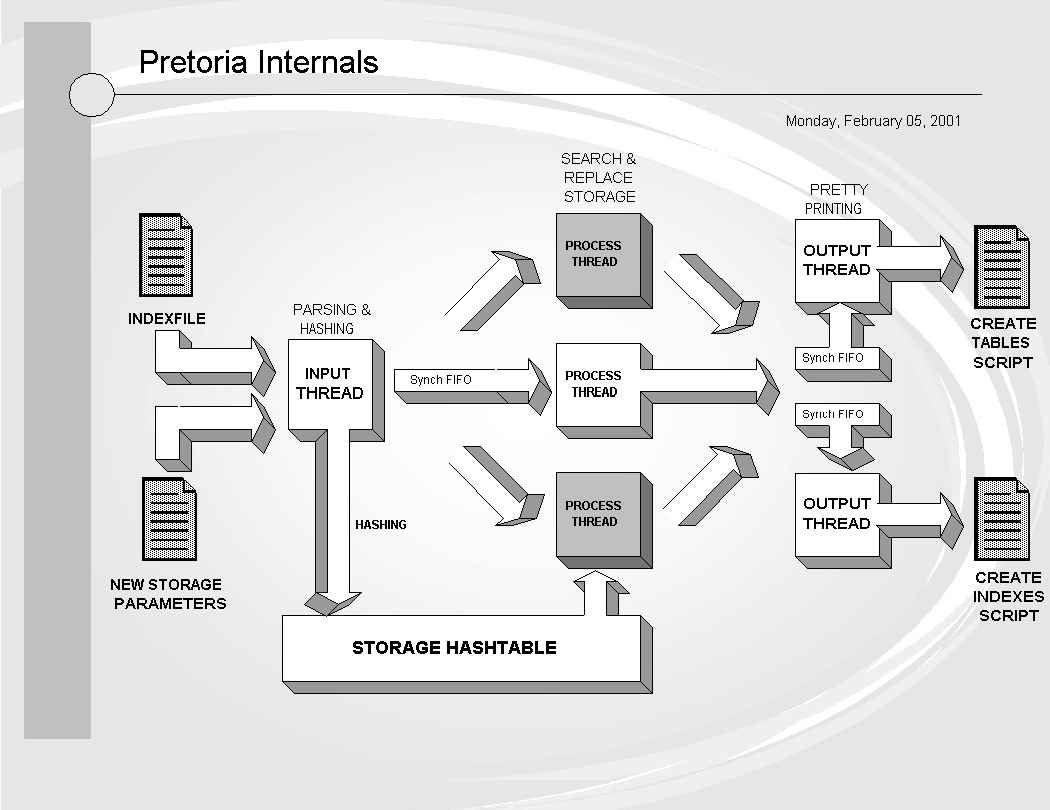
Pretoria needs 2 input files :
Oracle indexfile : an Oracle indexfile contains all table, cluster and index create statements. However, only the create index statements are uncommented. Typically an indexfile is used to manually create your indexes after an import or to reorganize your indexes - for example by modifying parameters such as initial extent, next extent, pctused, pctfree, tablespace ... Because the indexfile also contains table information it can also be used to reorganize your tables. However, it's often a tedious task to modify the storage parameters for a large number of tables.
A file containing new storage parameters for segments : this file can easily be create using some PL/SQL and the UTL_FILE package. Using PL/SQL you can enforce some basic rules on all database segments. For example you could choose to recalculate initial and next extents of a segment, based on the size of the segment, and the number of datafiles of the tablespace the segment resides in. Why ? I tend to spread datafiles over multiple disks and controllers. Oracle will automatically stripe extents over the available datafiles - for VLDB this gives excellent performance using PQ slaves.
Input thread
The input thread will parse the storage parameter file and hash all parameters using the segment name as a hashkey.
After hashing the storage parameters the input thread will parse the indexfile - all statements will be put in a synchronized FIFO.
Starting from Pretoria 3a a pre-parser was added (great idea by Stéphane Duprat) - the pre-parser adds white spaces in front and after the tokens '(', ')' and ','. This makes Pretoria more stable for future Oracle releases.
Process threads
Currently only one process thread will be spawned - however, I'm currently working on a version using multiple process threads as it's a great exercise on multithreading and makes the program look cool in general ;-)
A process thread will perform search and replace operations on all statements coming out of the FIFO. Basically a hash join is done using the storage hash. The advantage here is performance - the disadvantage is the size of the hashtable for a large amount of segments and storage parameters.
The process thread will also separate 'table create' and 'index create' statements. After processing the statements will be placed into 2 different synchronized FIFO's - this way, 2 dedicated output threads can be used.
Output threads
Two output threads are spawned. One will read 'table create' statements out of a FIFO - the other one will read 'index create' statements out of another FIFO (default).
Both threads do some pretty printing stuff - however, this was not my main intention and therefore I didn't give it much thought. So if the output looks a bit funny to you, remember that everything is better than the initial indexfile !!!
Output is written to files using a buffered output stream.
Starting from Pretoria 2a there are additional output modes - see Running Pretoria
Pretoria does not use parse trees nor does it make use of the railroad diagrams found in SQL reference books. This is also the reason why the pretty printing stuff is pretty lame. Also - not lexical parsing is done !
1. As an Oracle DBA/Consultant I don't do a lot of programming - except for the usual Ksh scripting and PL/SQL stuff. So when I program something it has to be something fun or I lose interest very easily ( I guess my ex colleagues can confirm this ? :-) ). That's the main reason for using threads and FIFO's as inter-thread communication - it's fun !
2. Depending on your hardware and platform, performance - can - increase using threads. If you run multi-threaded programs on an SMP box (multiple processors), your OS will run multiple threads concurrently on multiple processors. This all depends on the implementation of the native thread library. However several operating systems implement the two-level thread model - for example IBM AIX, HP-UX, Solaris, Digital Unix (Tru64).
Pretoria is written using JDK1.3. However, all code is 1.1.x compliant.
I used Java in general because it's platform independent. We had a Ksh script (written by my good friend Kugendran Naidoo) using kick ass awk/sed/grep text manipulations doing exactly the same (well almost) thing however :
Several platforms have minor differences in awk/sed/grep that screw up the script
Modifying storage parameters of a 90000 segments SAP DB took 3 days (if I'm not mistaking) on an Intel PIII Linux box (when Kugendran rewrote it using parallel processes it took only 30min :-) )
It doesn't work on MS NT (duh)
So, using Java these aren't issues anymore !
Another reason is - it's a language I pretty much know by heart. I've been using Java since version 1.0.1 and up for several projects as a software engineer.
As said before - it's a file containing create statements for tables, indexes and clusters.
REM CREATE TABLE
"PORTAL30"."WWV_SYS_APPLICATION_TEMPLATES$"
("ID"
REM NUMBER(*,0), "TEMPLATE_SCHEMA" VARCHAR2(30) NOT NULL ENABLE,
REM "TEMPLATE_NAME" VARCHAR2(50) NOT NULL ENABLE, "TEMPLATE_TYPE"
REM VARCHAR2(50) NOT NULL ENABLE, "CREATED_BY" VARCHAR2(30), "CREATED_ON"
REM DATE, "UPDATED_BY" VARCHAR2(30), "UPDATED_ON" DATE)
PCTFREE 10
REM PCTUSED 40 INITRANS 1 MAXTRANS 255 LOGGING STORAGE(INITIAL 16384 NEXT
REM 24576 MINEXTENTS 1 MAXEXTENTS 505 PCTINCREASE 50 FREELISTS 1 FREELIST
REM GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "PORTAL" ;
CREATE UNIQUE INDEX "PORTAL30"."WWV_SYS_APP_TEMPLS$_PK"
ON
"WWV_SYS_APPLICATION_TEMPLATES$" ("ID" ) PCTFREE 10 INITRANS
2 MAXTRANS
255 STORAGE(INITIAL 40960 NEXT 40960 MINEXTENTS 1 MAXEXTENTS 505
PCTINCREASE 50 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT)
TABLESPACE "PORTAL" LOGGING ;
REM ALTER TABLE "PORTAL30"."WWV_SYS_APPLICATION_TEMPLATES$"
ADD
REM CONSTRAINT "WWV_SYS_APP_TEMPLS$_PK" PRIMARY KEY ("ID")
USING INDEX
REM PCTFREE 10 INITRANS 2 MAXTRANS 255 STORAGE(INITIAL 40960 NEXT 40960
REM MINEXTENTS 1 MAXEXTENTS 505 PCTINCREASE 50 FREELISTS 1 FREELIST
REM GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "PORTAL" ENABLE ;
REM ALTER TABLE "PORTAL30"."WWV_SYS_APPLICATION_TEMPLATES$"
ADD
REM CONSTRAINT "WWV_SYS_APP_TEMPLS$_CK1" CHECK (template_type in
REM ('STRUCTURED', 'UNSTRUCTURED')) ENABLE NOVALIDATE ;
REM CREATE TABLE "PORTAL30"."WWV_SYS_APP_TEMPLATE_DETAILS$"
REM ("APP_TEMPLATE_ID" NUMBER(*,0), "ELEMENT" VARCHAR2(50),
"THE_VALUE"
REM LONG) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 LOGGING
REM STORAGE(INITIAL 65536 NEXT 40960 MINEXTENTS 1 MAXEXTENTS 505
REM PCTINCREASE 50 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT)
REM TABLESPACE "PORTAL" ;
CREATE INDEX "PORTAL30"."WWV_SYS_APP_TMPL_DET$_IDX" ON
"WWV_SYS_APP_TEMPLATE_DETAILS$" ("APP_TEMPLATE_ID" ) PCTFREE
10 INITRANS 2
MAXTRANS 255 STORAGE(INITIAL 16384 NEXT 24576 MINEXTENTS 1 MAXEXTENTS 505
PCTINCREASE 50 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT)
TABLESPACE "PORTAL" LOGGING ;
REM CREATE TABLE "PORTAL30"."WWV_SYS_BUILDER_DETAILS$"
("ID" NUMBER(*,0)
REM NOT NULL ENABLE, "NAME" VARCHAR2(40) NOT NULL ENABLE, "ARRAY_GROUP"
REM VARCHAR2(40), "TYPE_ID" NUMBER(*,0) NOT NULL ENABLE, "SEQ"
NUMBER NOT
REM NULL ENABLE, "SECTION" NUMBER NOT NULL ENABLE, "INPUT_TYPE"
REM VARCHAR2(10) NOT NULL ENABLE, "INPUT_WIDTH" NUMBER NOT NULL
ENABLE,
REM "INPUT_HEIGHT" NUMBER NOT NULL ENABLE, "COL_SPAN"
NUMBER, "ATTRIBUTE"
REM VARCHAR2(1), "REQUIRED" VARCHAR2(1), "DEF_ALLOWED"
VARCHAR2(1),
REM "IMPACT" VARCHAR2(1), "ARRAY" VARCHAR2(1), "LONG_TYPE"
VARCHAR2(1),
REM "LOVNAME" VARCHAR2(4000), "PRE_FUNCTION"
VARCHAR2(500),
REM "POST_FUNCTION" VARCHAR2(500), "PROMPT"
VARCHAR2(200),
REM "DEFAULT_VALUE" VARCHAR2(4000), "PROMPT_ALIGN"
VARCHAR2(10),
REM "UPPERCASE" VARCHAR2(1)) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS
REM 255 LOGGING STORAGE(INITIAL 573440 NEXT 147456 MINEXTENTS 1
REM MAXEXTENTS 505 PCTINCREASE 50 FREELISTS 1 FREELIST GROUPS 1
REM BUFFER_POOL DEFAULT) TABLESPACE "PORTAL" ;
REM ALTER TABLE "PORTAL30"."WWV_SYS_BUILDER_DETAILS$"
MODIFY
REM ("INPUT_WIDTH" DEFAULT 1 ) ;
REM ALTER TABLE "PORTAL30"."WWV_SYS_BUILDER_DETAILS$"
MODIFY
REM ("INPUT_HEIGHT" DEFAULT 1 ) ;
REM ALTER TABLE "PORTAL30"."WWV_SYS_BUILDER_DETAILS$" MODIFY
("UPPERCASE"
REM DEFAULT 'N') ;
CREATE UNIQUE INDEX "PORTAL30"."WWV_SYS_BUILDER_DETAILS$_PK"
ON
"WWV_SYS_BUILDER_DETAILS$" ("ID" ) PCTFREE 10 INITRANS 2
MAXTRANS 255
STORAGE(INITIAL 122880 NEXT 40960 MINEXTENTS 1 MAXEXTENTS 505 PCTINCREASE
50 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE
"PORTAL"
LOGGING ;
As you can see - it's crap - but very useful crap !!! Only the create index statements are uncommented ! Now you could start hacking away on the indexfile using your favorite text editor (vi) orrrrr you could use Pretoria !
An indexfile is created using Oracle's export/import utilities.
>> exp system/manager FULL=Y ROWS=N FILE=export.dmp
No need to export data here - just a logical export will do.
>> imp system/manager FILE=export.dmp FULL=Y INDEXFILE=index.sql
Don't worry - nothing will be imported into your database ! It'll just create the indexfile !
Note : on NT/Win2000 platforms the export/import executables are named differently - they always have stupid version numbers or something in their name : for example exp23 or exp8 ... It always confuses me too (but who runs a real database on NT anyway ?)
The storage parameter file can be created in different ways. But one thing is for sure - YOU will have to do it using creating storage rules YOU find appropriate. One could use PRO*C, PRO*COBOL, JDBC (Java) or whatever. For me the fasted way (and most platform independent) was ordinary PL/SQL using UTL_FILE package.
I've included a sample script called storage_rules.sql. It basically is going to query the size of all tables, indexes and table partitions and recalculated initial extent, next extent, pctincrease and parallel degree. I've made decisions based on the segment's SIZE found in DBA_SEGMENTS. This can be incorrect as it is based on the number of allocated extents - and not the actual data. A better way to do it is :
Although I already have a script like this, I did not include it as it's not necessary for explaining the principles. (And if you're a DBA it should be a piece of cake to write such a script - sometimes you have to work for your money :-) )
Quite handy is the fact that the storage parameter file can contain database users passwords. If you look at an indexfile you'll notice CONNECT <<user>> statements. However, the indexfile doesn't add the passwords. This would normally mean walking through the whole file using your favorite text editor and adding user passwords (or else suffer 'No longer connected to Oracle' warnings!). In other words - you can list users password using following syntax :
CONNECT <<username>> <<password>>
CONNECT SYSTEM MANAGER
Only use whitespaces and/or tabs as separators.
Listing storage parameters :
"OWNER"."SEGMENTNAME"."PARTITIONNAME" <<storage parameter 1>> <<value 1>> <<storage parameter n>> <<value n>>
The first token on a line should always be owner + segmentname + partitionname (optional) as it'll be used as a hashkey. Always use double quotes (") and dots (.) to separate owner, segmentname and partitionname (optional).
<<storage parameter>> is one of the following :
All storage parameters have to be listed in UPPERCASE. Two parameters are currently not supported - buffer pool. This parameter can also be set using an ALTER TABLE command and should only be changed after a database tuning and splitting up your buffer cache. The other parameter is INSTANCES - this parameters is usefull for Oracle Parallel Server. It defines the number of instances in an OPS setup that will take part of running a query (inter-instance parallelism). Modify this parameter only when you're migrating from OPS to Single Instance or vice versa (after tuning).
You do not have to list the storage parameters in any particular order !
A lot of people have asked me to add the ability to work with wildcards. Starting from Pretoria 3a I've added the next best thing : DEFAULT values. This feature was partially implemented by Stéphane Duprat - I just optimised the code a bit and made it work for all 3 object types (TABLE, INDEX, CONSTRAINT).This feature introduced some extra keywords :
These 3 new keywords are quite self-explaining. If Pretoria can not find an entry for a particular object (table, index, constraint), it'll look for DEFAULT storage parameters of that object's owner.
If Pretoria can not find an entry for a particular object, and also no entry for the DEFAULT value for that object's owner, Pretoria will look for an overall DEFAULT value for that object's type.
Example :
"DWH"."CUSTOMERS" INITIAL 100M NEXT 100M PCTFREE 5 TABLESPACE CUST
DEFAULT_TABLE("DWH") INITIAL 1M NEXT 1M TABLESPACE DWH_DATA
DEFAULT_TABLE ("DWHADMIN") INITIAL 512K NEXT 512K TABLESPACE DWH_ADMIN_DATA
DEFAULT_TABLE INTIAL 128K NEXT 128K TABLESPACE DATA
"DWH"."CUSTOMERS_IDX" INITIAL 20M NEXT 20M TABLESPACE CUST_IDX
DEFAULT_INDEX("DWH") TABLESPACE INDEX DWH_INDX
DEFAULT_INDEX TABLESPACE INDX
Using the above as a storagefile for Pretoria, the following things will happen :
If you downloaded the source code (Pretoria.java), you first have to compile it. You can do this by invoking javac :
javac Pretoria.java
javac is not part of JRE (java runtime environment). You need a JDK (java development kit) to compile.
Pretoria 1x
java -classpath Pretoria.jar Pretoria <indexfile> <storagefile> <table output file> <index output file>
java -classpath Pretoria.jar Pretoria -p <indexfile> <table output file> <index output file>
Using -p, Pretoria will only perform its pretty printing functionality - no storage file is needed.
Pretoria 2x
Pretoria 2a introduces new output modes - and thus, new command line switches :
Examples :
If you're using JRE (Java Runtime Environment) instead of JDK (Java Development Kit) it's possible that you'll have to invoke jre instead of java.
Because the output threads add platform specific line separators, you can get into trouble using SQL*Plus. I would recommend running the table & index create script as SYSTEM in Server Manager (svrmgrl / svrmgr23 / svrmgr30) on pre 8i version. From 8.1.5 on you can use SQL*Plus but perform 'set SQLBLANK on' first !!!
In short - following these steps :
This is quite simple - If you want further assistance you can always contact me...
Our current record for reorganizing a
is 10 hours !!!
We used our own proprietary tool (massive parallel export/import) for exporting and importing the data. The 10hours do not include database monitoring to define our storage rules ! We also improved our proprietary export/import tool (thanks again to Kugendran Naidoo) so it should even go faster now.
The reorganization was only a part of an OPS (12 nodes) migration to Single Instance Oracle setup. We first moved the warehouse from an IBM RS6000 SP2 using EMC storage and raw devices to the IBM S80/ESS on JFS - this phase took only 5hours for the database to start up. Afterwards, we recreated the warehouse using bigger db blocks, going from 8.0.4 32bit to 8.1.6 64bit, full export/import. The warehouse was down for less than a weekend ! Performance gains were unbelievable - some reports that took 3days to finish now ran within one minute :-) You do the math !
Anyone beating our record - let me know and I'll send you a real belgian beer !
People interested in our services can always contact me.
Oh - this was back in the magical year 2000 !!!
This program was written during 2 days - I had the flue ... and got bored - so I wrote this small program. I've only tested it briefly on MS Win, Linux, IBM AIX, Compaq Tru64 and HPUX11 using JDK 1.1.5, 1.1.8, 1.2 and 1.3 and indexfiles coming from Oracle RDBMS 7.3.4, 8.0.4, 8.1.6 and 8.1.7 (32 & 64 bit), 9i (64bit). So make no illusions - I'm pretty sure it'll contain bugs as I'm a DBA and thus inherently lazy . If you find one, or if you have a request or a great idea - let me know ! My email address is kurt_van_meerbeeck@axi.be
Pretoria is free of charge !!!
My personal webpage is http://zap.to/knal !
Cheers
Kurt.